7 ANOVA explained
7.1 The basic principles of ANOVA
There are many varieties of ANOVA but we will start with the simplest.
We would carry out a ‘One-way’ ANOVA (ANalysis Of VAriance) when we have independent replicates from three or more populations and we want to know if there is evidence for a difference between at least one pair of these in respect of the mean value of a numerical variable in which we ae interested. There almost certainly will be a difference between the sample means but these samples are just that - samples - randomly (we hope) drawn from their respective populations. If we drew three samples from the same population they would also almost certainly differ in their means! The differences are due to the random variation within the populations and our random method of choosing samples from them.
What we want to know is whether the differences we see between our samples are big enough for us to reject the null hypothesis that there is no difference between the populations - that they are, in effect, the same population.
Here we will go through an example in detail and work out all the mechanics, but once we have done that and seen how the output is derived from the input we will not need to do it again. We will use R to do the heavy lifting. We will just need to know when it is appropriate to use ANOVA, how to get R to do it and how to interpret the output that R produces.
An ANOVA analysis (bit like saying MOT test!) attempts to determine whether the differences between samples are significant by investigating the variability in the data. It investigates how the variability between samples compares to the variability within samples.
7.1.1 The Scenario
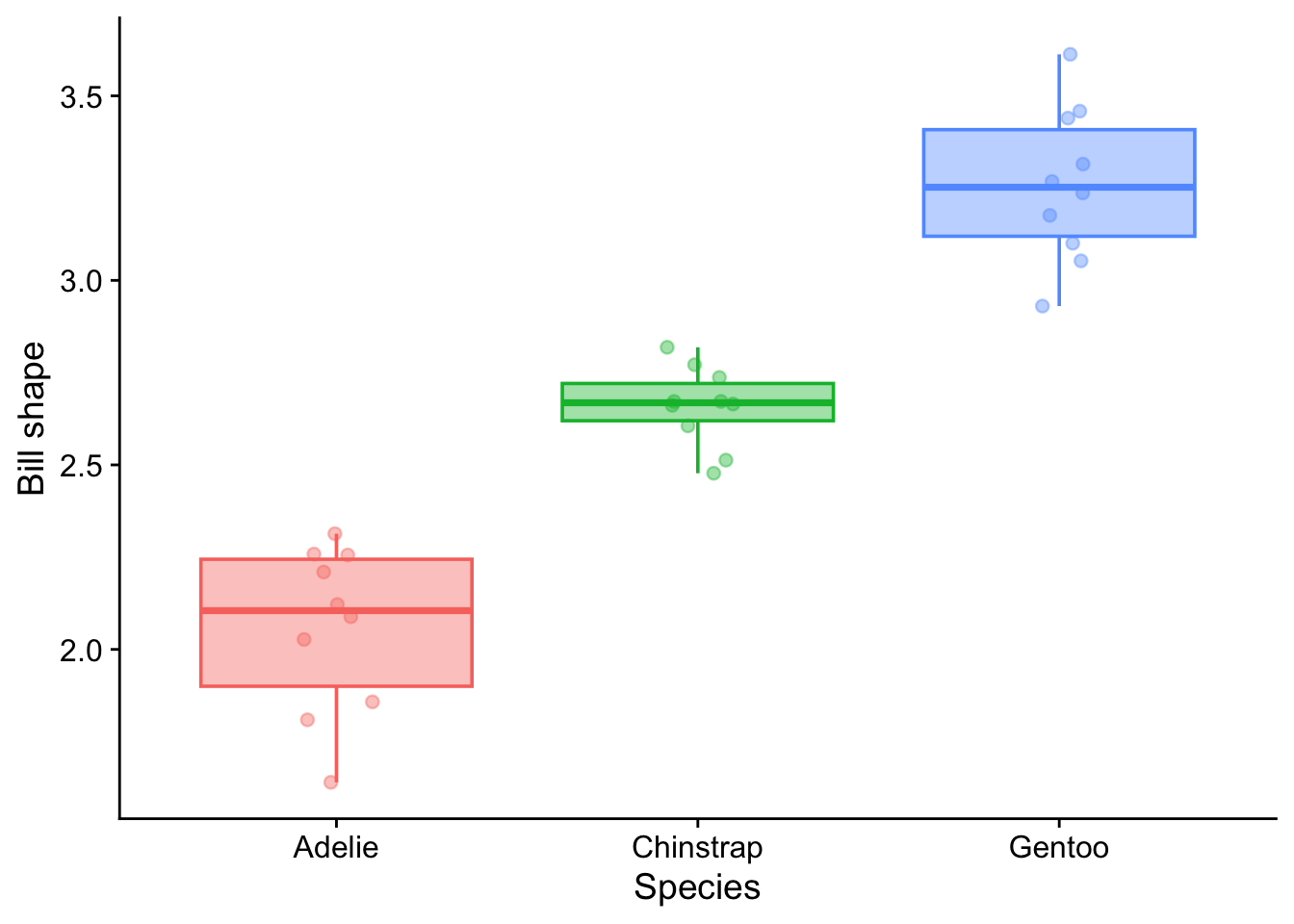
As our case study we consider the three species of penguin, Adelie, Chinstrap and Gentoo for which data has been gathered and made available in the palmerpenguins R package. For dozens of individuals of each species, records have been logged of the species, sex, year, bill length, bill depth, flipper length and body mass. Suppose we are interested in the shape of the bills and so create for each individual a new variable which is the ratio of bill length to bill depth. We wish to know if there is evidence from the data for whether this bill shape differs between the species. In the manner of the bills of the various species of finch spread across the islands of the Galapagos archipeligo, this might indicate a different food source for each species and more generally, indicate that each species occupies a different ecological niche from the others.
When we plot the data as in Figure 7.1 we see that the species do differ in their bill shapes but that there is also a lot of variation between penguins of the same species.
7.2 Summarise the data: calculate means
First step: calculate the grand mean
First we calculate the ‘grand mean’, the mean of the bill shapes across all penguins in the data set:
[1] 2.658853Second step: calculate the group means
Next, we calculate the mean bill shape for each species - these are what we will call the group means.
# A tibble: 3 × 5
species n pmean id_min id_max
<fct> <int> <dbl> <int> <int>
1 Adelie 10 2.06 1 10
2 Chinstrap 10 2.66 11 20
3 Gentoo 10 3.26 21 307.3 Calculate variabilities around the means: sums of squared differences
Now we can calculate and plot the deviations of the data around these means. That will allow us to visualise and calculate what turn out to be the key quatities in carrying out an ANOVA analysis: the sums of squared differences. There are three of these and we will turn to them now:
7.3.1 SST: the total sum of squares
FRom the deviations of each individual arounnd the grand mean we can calculate what we will call SST: the total sum of squares. This is the sum of the squared differences between each individual penguin bill shape and the grand mean. In this and other measures of variability we square the differences so that we do not distinguish between positive and negative deviations.
SST is a measure of the total variability of the data set. For our penguins we find that SST = 8.147
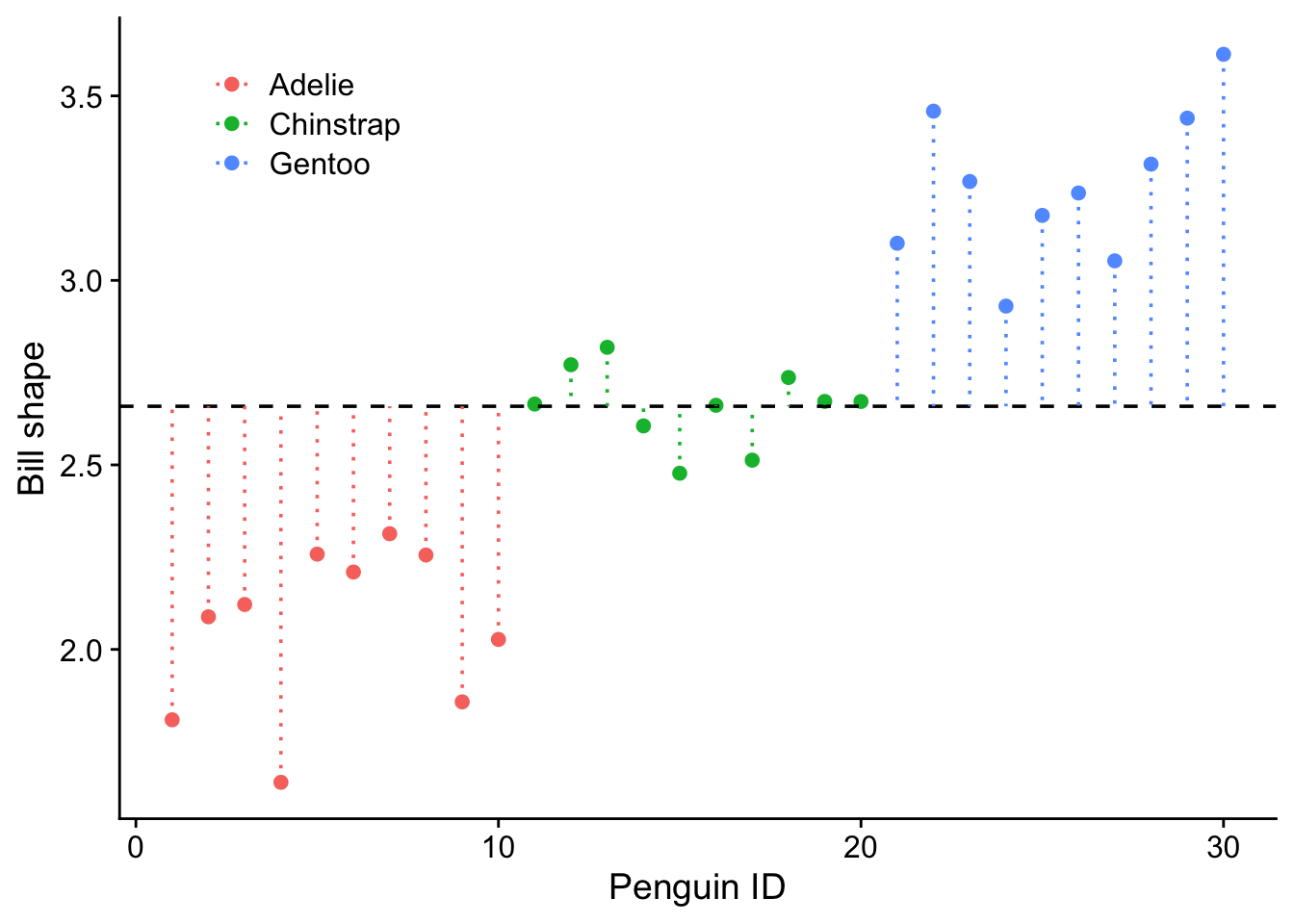
Now we determine two more measures of variability: the deviations of individual penguins from their group means, and the the deviations of those group means from the grand mean. For each of these measures, we will square them so that we do not distinguish between positive and negative deviations, and then sum these squares to get a measure of the total variabilities.
7.3.2 SSE - Error sum of squares
SSE is the error sum of squares. It is the sum of the squares of the deviations of the data around the three separate species means. This is a measure of the variation between individuals of the same species.
7.3.3 SSG - group (species) sum of squares
SSG is the group sum of squares. This is the sum of the squares of the deviations of the group (species, in this case) means from the grand mean. This is a measure of the variation between individuals of different species.
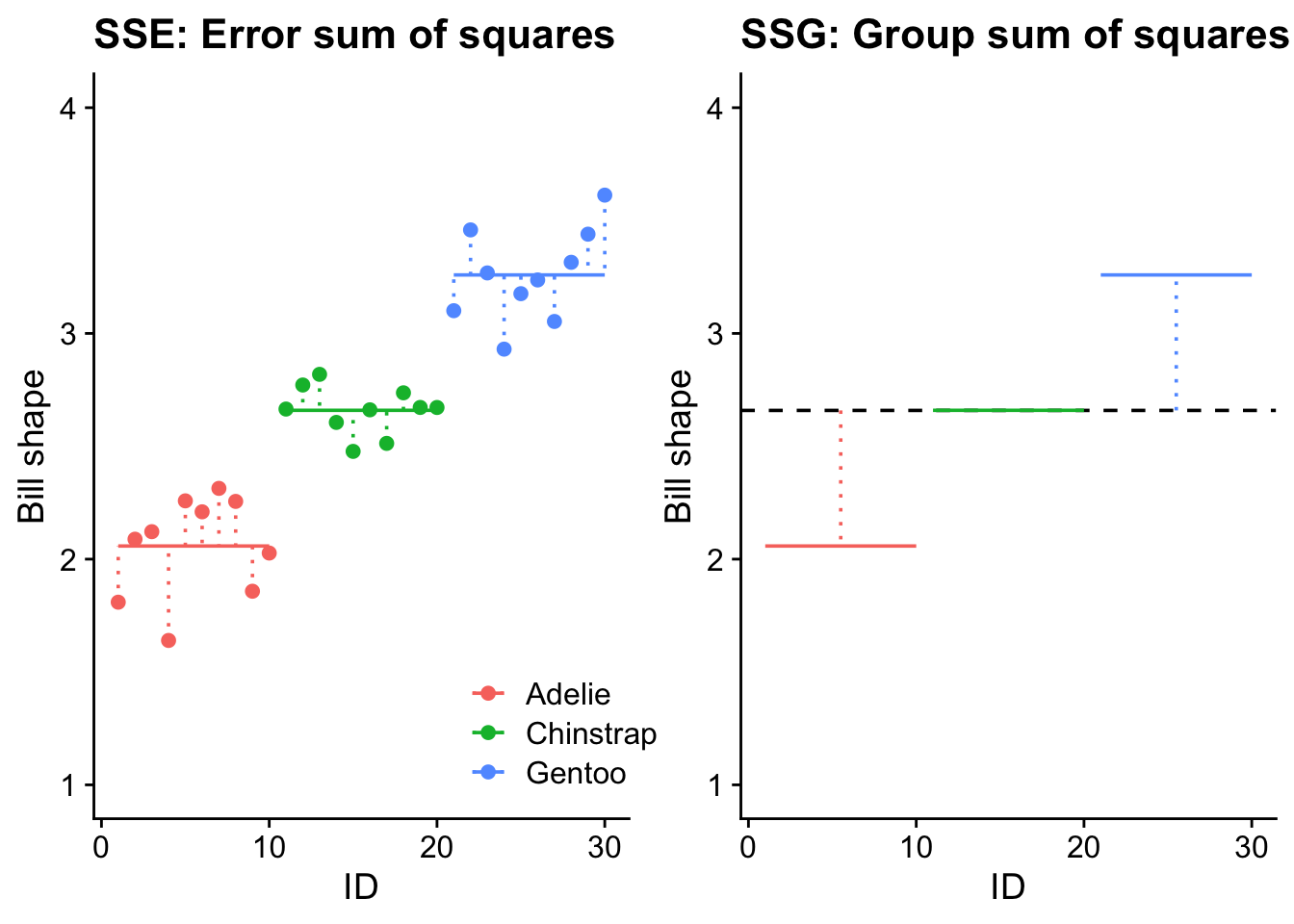
When the three species means are fitted, there is an obvious reduction in variability around the three means compared to that around the grand mean: SSE is less than SST, but it is not obvious if bill shape differs between the species.
At what point do we decide if the amount of variation explained by fitting the means is significant? By this, we mean, “When is the variability between the group means greater than we would expect by chance alone?
First, we note that SSE and SSG partition between them the total variability SST in the data:
7.4 Partitioning the sums of squares: SST = SSE + SSG
| Sum of Squares | Value |
|---|---|
| SSE | 0.936 |
| SSG | 7.212 |
| SST | 8.147 |
| SSE + SSG | 8.148 = SST |
So the total variability has been divided into two components. That due to differences between individuals of different species (SSG) and that due to differences between individuals of the same species. (SSE). Variability must be due to one or other of these components. Separating the total SS into its component SS is known as partitioning the sums of squares.
A comparison of SSG and SSE is going to indicate whether fitting the three species means accounts for a significant amount of variability.
However, to make a proper comparison, we really need to compare the variability per degree of freedom ie the variance, so first we need to discuss what we mean by degrees of freedom for each of the sums of squares calculated so far, and how we calculate them.
7.5 Partitioning the degrees of freedom
Every sum of squares (SS) has been calculated using a number of independent pieces of information. In each, case, we call this number the number of degrees of freedom for the SS.
For SST this number is one less than the number of data points n. This is because when we calculate the deviations of each data point around a grand mean there are only n-1 of them that are independent, since by definition the sum of these deviations is zero, and so when n-1 of them have been calculated, the final one is pre-determined.
Similarly, when we calculate SSG, which measures the deviation of the \(k\) species means from the grand mean, we have \(k\)-1 degrees of freedom, (where in the present example \(k\), the number of species, is equal to three) since the deviations must sum to zero, so when \(k\)-1 of them have been calculated, the last one is pre-determined.
Finally, SSE, which measures deviation around the group means will have n-k degrees of freedom, since the sum of each of the deviations around one of the group means must sum to zero, and so when all but one of them have been calculated, the final one is pre-determined. There are \(k\) group means, so the total degrees of freedom for SSE is n-k.
The degrees of freedom are additive:
\[ df(\text{SST}) = df(\text{SSE}) + df(\text{SSG}) \]
Check: \[ \begin{align*} df(\text{SST}) &= n-1\\ df(\text{SSE}) &= k-1\\ df(\text{SSG}) &= n-k\\ \therefore df(\text{SSE}) + df(\text{SSG}) &= k-1 + n-k\\ &=n-1\\ &=df(\text{SST}) \end{align*} \]
7.6 Variances per degree of freedom: Mean Squares
Now we can calculate the variances which are a measure of the amount of variability per degree of freedom.
In this context, we call them mean squares. To find each one we divide each of the sums of squares (SS) by its corresponding degrees of freedom.
Group Mean Square (GMS) = SSG / k - 1. This is the variation per df between individuals of different species.
Error Mean Square (EMS) = SSE / n - k. This is the variation per df between individuals of the same species.
Total Mean Square (TMS) = SST / n - 1. This is the total variance per df of the dataset.
Unlike the SS, the MS are not additive. That is, GMS + EMS \(\neq\) TMS as we see in the table below where we list these values for our penguins sample:
| Mean Square | Value |
|---|---|
| GMS | 2.73 |
| EMS | 0.0154 |
| TMS | 0.171 |
7.7 F-ratios
If species did not influence bill shape, we would expect as much variation between the penguins of the same species as between penguins of different species.
We can express this in terms of the mean squares: the mean square for groups (species) would be about the same as the mean square for error and so their ratio would be about equal to 1:
\[ F=\frac{\text{GMS}}{\text{EMS}}\approx1\quad{\text{No difference between groups}} \]
We call this ratio the F-ratio. This is the so-called ‘test statistic’ that ANOVA calculates from your data. F-ratios can never be negative since they are the ratio of two mean square values, both of which must be non-negative, but there is no limit to how large they can be. In fact,
\[ F = \frac{\text{GMS}}{\text{EMS}}\gt 1\quad{\text{Possible difference between groups}} \]
\[ F = \frac{\text{GMS}}{\text{EMS}}\gg 1\quad{\text{Probable difference between groups}} \]
Even if the species were identical, the F-ratio is unlikely to be exactly 1 - it could by chance take a whole range of values. It turns out that F-ratios have a known distribution, the F-distribution, which represents the range and likelihood of all possible F ratios under the null hypothesis. ie when the species were identical.
The shape of the F distribution depends on the degrees of freedom of GMS and EMS, and we normally specify it by giving the values of each. In Figure 7.4 below we show F distributions for 2 and 27 degrees of freedom (ie 3 species, so k = 3, so the degrees of freedom of GMS = k-1 = 2, and 10 individuals per species, so n = 3 x 10 = 30, and hence the degrees of freedom of EMS = n-k = 30 - 3 = 27), and for 10 and 27 degrees of freedom.
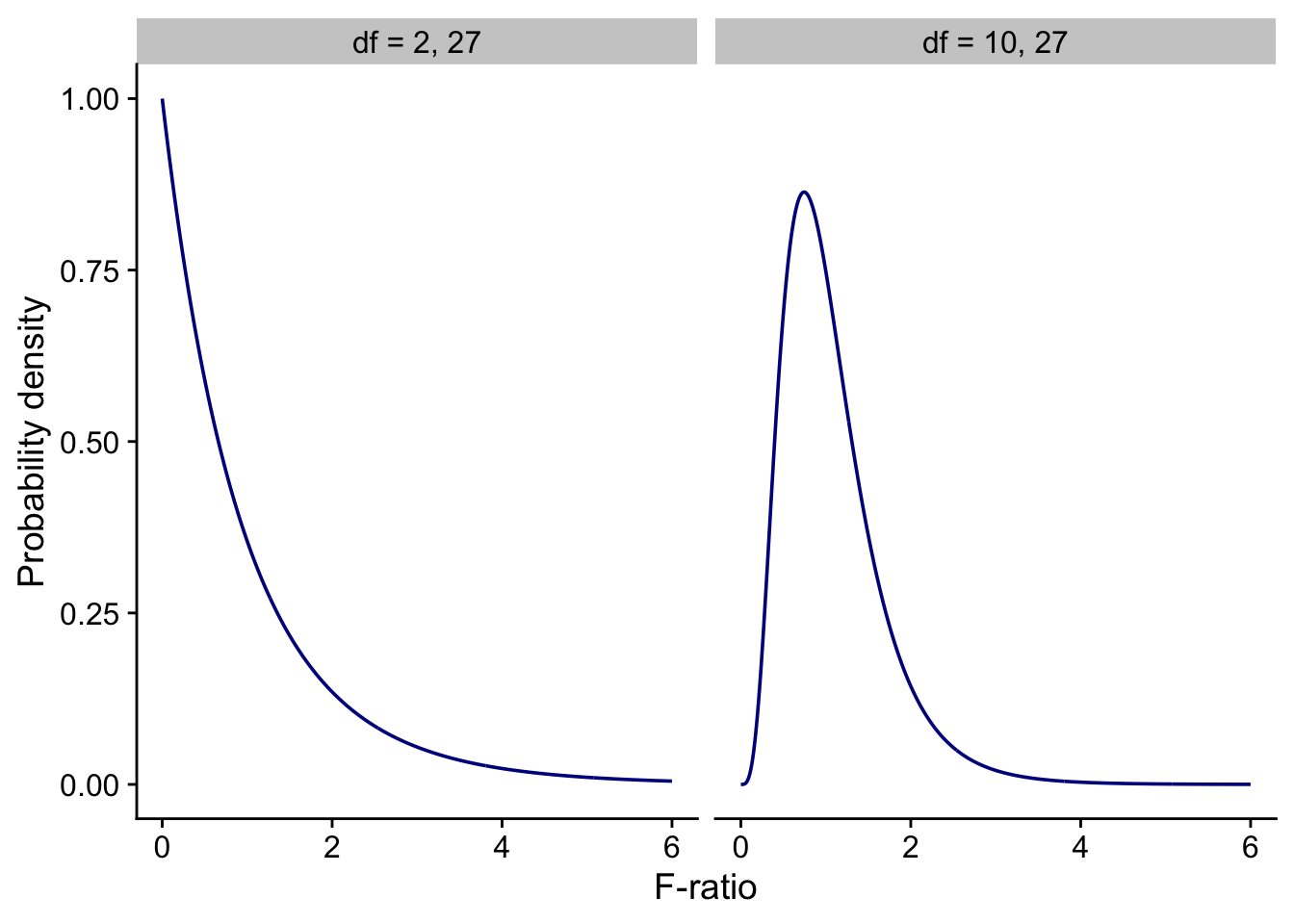
Note that, whatever the degrees of freedom, F-distributions are examples of so-called probability density functions. The area beneath them between any two values of F-ratio is equal to the probability of getting an F-ratio in that range. Hence the total area under the curves is equal to 1, since the F-ratio must take some value between zero and infinity, and the area under the tail to the right of any given F-ratio is the probability of getting an F-ratio bigger than that value.
Hence, the probability under the null hypothesis of getting an F-ratio as large or larger than the value we actually got is the area to the right of this F-ratio under the appropriate F distribution. We often call this probability the p-value. p for probability. p-values are the the probability of getting data as extreme (same F-ratio,) or more extreme (bigger F-ratio) as the data you got you got if the null hypothesis were true.
If the species were very different, then the GMS would be much greater than the EMS and the F-ratio would be greater than one. However it can be quite large even when there are no differences between the levels (here, Adelie, Chinstrap and Gentoo) of a factor (here, species). So how do we decide when the size of the F-ratio is due to a real difference between the levels rather than to chance?
Our p-value (the probability that the F-ratio would have been as large as it is or larger under the null hypothesis) represents the strength of evidence against the null hypothesis. The smaller it is, the stronger the evidence, and, as a pragmatic choice, only when it is less than 0.05 do we regard the evidence as strong enough to reject the null. Note though that even if we had inside knowledge that the null hypothesis was in fact true, we would still get an F-ratio that large or larger and thus a p-value less than or equal to 0.05 5% of the time.
We find for our penguin data that the F ratio is 104
If we look at the F distribution in the left-hand figure in Figure 7.4 the one that corresponds to our case, with 2 and 27 degrees of freedom, we see that it has already fallen to near zero by the time F is equal to 5 or 6. There is essentially zero area beneath the curve to the right of the much larger F value we found for our data, F = 104. That means there is essentially zero chance of getting an F value this big or bigger if the null hypothesis were true (ie the p-value is esentially zero), and so we can confidently reject the null hypothesis.
7.8 What does the ANOVA result tell us?
The null hypothesis of the ANOVA is that all the samples are drawn from populations with the same mean. If the F-value is so large that we reject this null hypothesis, then we infer that at least two of the population means differ. We not learn from the ANOVA where the difference or differences lie.
To find that out we typically need to continue the analysis with multiple pair-wise comparisons between the samples, taking care to control for the study-wide error rate.
Analysis of Variance Table
Response: bill_shape
Df Sum Sq Mean Sq F value Pr(>F)
species 2 7.2117 3.6058 104.05 2.05e-13 ***
Residuals 27 0.9357 0.0347
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1